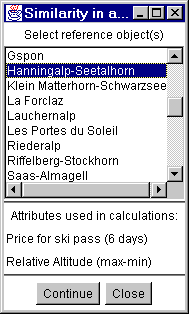
Abb. 1
Auswahl der Referenzobjekte
Kalkulation als multivariable Analysis
Similarity (distance) - Ähnlichkeiten
(Abstand)
Similarity (classification) -
Ähnlichkeiten (Klassifikation)
Dominant attribute
classification - Klassifikation nach dominierenden Attributen
Eine interessante und nützliche Art der Datenanalyse basiert auf der Berechnung des Ähnlichkeitsgrads oder des Abstandes der Objekte
in dem mehrdimensionalen Attributraum. Die Ähnlichkeitsanalyse kann die
Verteilung der Charakteristika auf einer Objektmenge verständlicher
machen.
Die Referenzobjekte werden aus einer Liste mit allen Objekten
ausgewählt (Abb. 1). Es ist auch möglich sie aus der Karte heraus per
Mausklick auszuwählen, wenn die entsprechende Schicht aktiv ist (roter
Kasten in der Legende).
Abb. 1
Auswahl der
Referenzobjekte
Descartes bietet mehrere Kalkulationsmethoden des Abstandes zwischen
Objekten, basierend auf verschiedenen Metriken. Die Berechnungsergebnisse
können an einem Graphen mit parallelen Koordinaten mit Achsen für die
Ursprungsattributen und einer Achse für den Abstand (Abb. 2). Man kann
leicht die Linie des Referenzobjektes finden und sie mit den Linien der anderen
Objekte vergleichen. Eine Möglichkeit dafür ist die dauerhafte und
vorübergehende Markierung. Deß weiteren kann das Diagramm so
verändert werden, daß das Referenzobjekt durch eine gerade Linie
präsentiert wird.
Im letzteren Fall werden alle Achsen verschoben, ohne
ihren Maßstab zu verändern. Diese Präsentationsmethode
erleichtert das Verständnis und die Untersuchung der Berechnungsergebnisse.
Je näher eine Linie der geraden Referenzlinie ist, desto ähnlicher
ist es dem Referenzobjekt. Der Benutzer hat die Möglichkeit die Parameter,
z.B. die zugrunde liegende Metrik der Berechnung zu verändern. Jede
Veränderung wird sofort auf dem Diagramm sichtbar.
Die verschiedenen verfügbaren Metriken sind:
L1:
Dist(A,B)=Sum(Abs(Ai-Bi))
L2: Dist(A,B)=Sqrt(Sum(Ai-Bi)^2))
C:
Dist(A,B)=Max(Abs(Ai-Bi))
T: Spezielle Metrik für Zeitreihen. Sie gibt
die Anzahl der Momente, in denen eine ähnliche Wertänderung
stattgefunden hat. Diese Metrik sollte ausschließlich auf Zeitreihen
angewendet werden!

Abb. 2
"Parallel coordinate plot"
für Ähnlichkeitsberechnungen durch den Abstand
Das Kartenfenster ändert sich ebenfalls. Die Objekte (in Abb. 3: Skiregionen) sind in Farbschattierungen abgebildet (nähere Beschreibung hier).
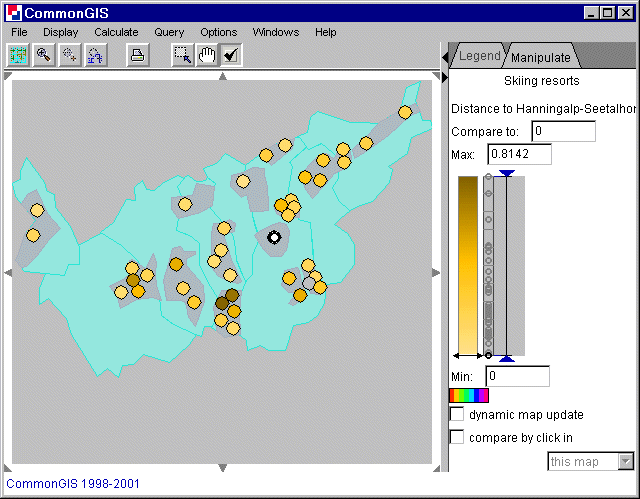
Abb. 3
Visualisierung der
mit Abstand berechneten Ähnlichkeiten
Auf der Basis der Abstandsberechnungen kann man nun eine weitere
untersuchende Datenanalyse Aufgabe angehen: Klassifizierung von Objekten in
zwei Klassen, vertreten durch Repräsentanten.
Das Verfahren der
Klassifikation wird auf folgende Weise durchgeführt:
Zu jedem Objekt
berechnet das System die Abstände DI und DII zu den Repräsentanten
der zwei Klassen I und II. Falls für ein Objekt min(DI,II)>d0 gilt, mit
Grenzwert d0, so wird dies keine der zwei Klassen zugeteilt (es ist beiden
Repräsentanten nicht ähnlich). Andernfalls wird das Objekt der Klasse
I zugeteilt, wenn DI<DII, oder der Klasse II, wenn DI>II. Man kann
zwischen verschiedenen Metriken für die Berechnung der Abstände
wählen und die Parameterwerte ändern. Um d0 zu setzten kann man den
Schieber bei "distance threshold for classification" verschiebt. Der momentane
Wert kann rechts von der Skala abgelesen werden.
Das Verfahren der
ähnlichkeitsbasierten Klassifikation kann vom einem Graphen mit parallelen Koordinaten
unterstützt werden. Das Diagramm enthält Achsen für alle
ursprünglichen Attribute, dem Abstand zu den Klassen I und II, sowie das
Ergebnis der Klassifikation. Letzeres wird mit Zahlen versehen: -1 steht
für die Klasse I, 1 für die Klasse II und 0 für
nichtklassifizierte Objekte. Die Achsen sind so formatiert, daß die
Linien der zwei Repräsentanten der Klassen gerade sind (dies ist
möglich falls alle Werte aller Attribute dieser zwei Objekte verschieden
sind). Die Skala jeder Achse ist durch die Differenz der Attributwerte
der Referenzobjekte I und II begrenzt. Die Orientierung einer Achse kann schon mal von
rechts nach links gehen, um den Refernzwert des Referenzobjektes I links von
dem Referenzobjekt II abbilden zu können. Die Erscheinung des Diagramms
wird in Abb. 4 gezeigt.
Das so transformierte Diagramm zeigt die Resultate
der Klassifikation auf einfache Weise. Falls eine Linie in der Nähe der
Linie eines Referenzobjektes ist, so gehört das Objekt auch zu der selben
Klasse. Falls eine Linie sehr von den Linien beider Referenzobjekte abweicht,
so ist dieses Objekt nichtklassifiziert.
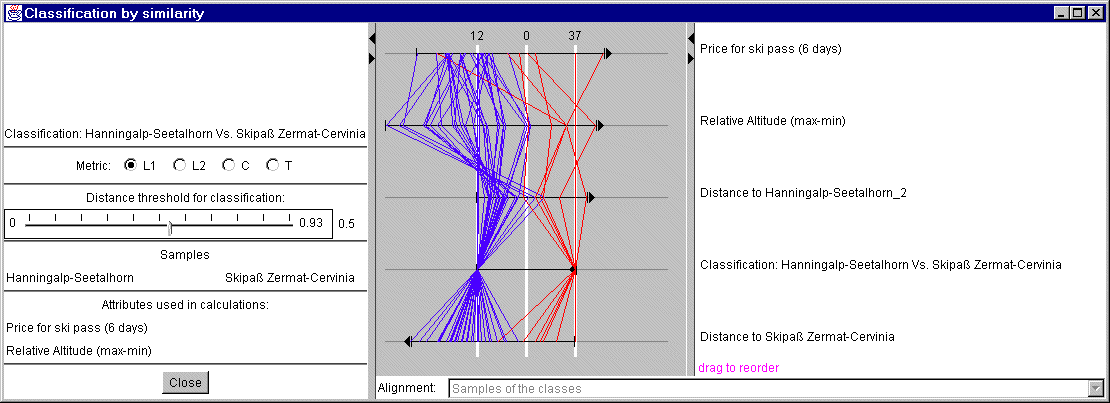
Abb. 4
"Parallel coordinate plot" der
Klassifikation durch Ähnlichkeit
Werden geographisch zugeordnete Daten analysiert, so kann man das
Ergebnis der Klassifikation auch auf der Karte betrachten (siehe Abb. 5). Die
Objekte werden in den verschiedenen Farben der Klassen I, II oder gar keiner
(grau) dargestellt.
Die Linien in der Abb. 4 sind blau und rot, da das
Kästchen "Broadcast classifikation" (Übertrage Klassifikation)
aktiviert in Abb. 5 aktiviert worden ist.
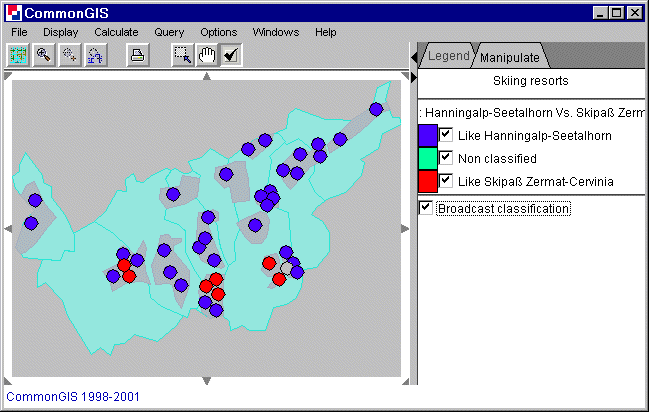
Abb. 5
Visualisierung der Klassifikation
durch Ähnlichkeit
Dominant attribute classification
Diese Methode ermittelt das dominierende Kriterium (Minimum oder Maximum) von jedem Objekt (Abb. 6).
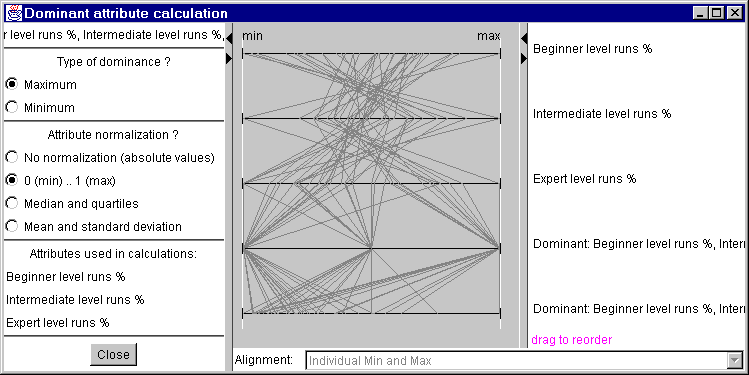
Abb. 6
"Parallel coordinate plot" des
dominierenden Attribut
Die Erscheinung des Diagramms kann durch Normierung verändert werden:
| No normalization (absolute values) | Attribute werden auf einer einzelnen Skala mit ihrem absoluten Werten, ohne Normierung, dargestellt. |
| 0 (min) ... 1 (max) | Attribute werden auf eine Skala von 0.0 bis 1.0 projiziert. 0.0 entspricht dem Minimum und 1.0 dem Maximum jedes Attributes. |
| Median and quartiles | Attribute werden auf einer Skala dargestellt, wo der Mittelwert und die Viertelwerte jedes Attribute ausgerichtet sind. |
| Mean and standard deviation | Attribute werden auf eine Skala projiziert wo die Mittelwerte jedes Attributs in der Mitte ausgerichtet sind und wo die mittleren Standardabweichungen +/-1 ebenso ausgerichtet sind. |
Für jedes Objekt wird das dominierende Attribut in einer bestimmten Farbe abgebildet. Die Farben können durch einen Mausklick auf das farbige Kästchen in dem Manipulationskarteifenster geändert werden. Das Kästchen daneben kann einzelne Attribute an-, oder ausschalten (betrifft alle Fenster).
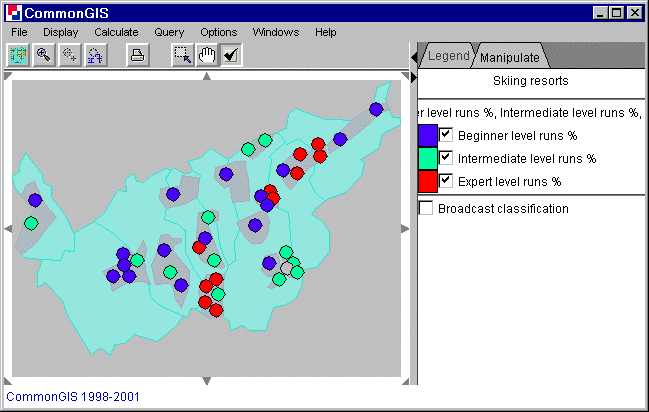
Abb. 7
Visualisierung der dominierenden
Attributsberechnung
Ist das Kästchen "Broadcast classification" aktiviert, so werden alle Punkte oder Linien aller Diagramme die selben Farben haben, wie auf dieser Karte.